ACL 2026 · Long Paper
Efficient Test-Time Scaling
via Probing Internal States
of Large Language Models
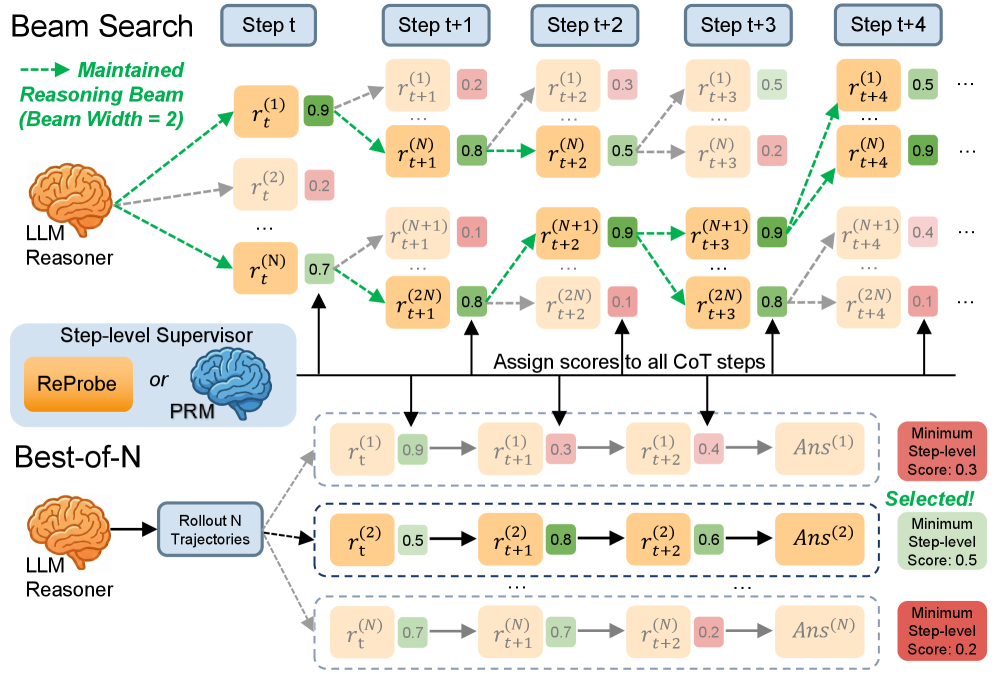
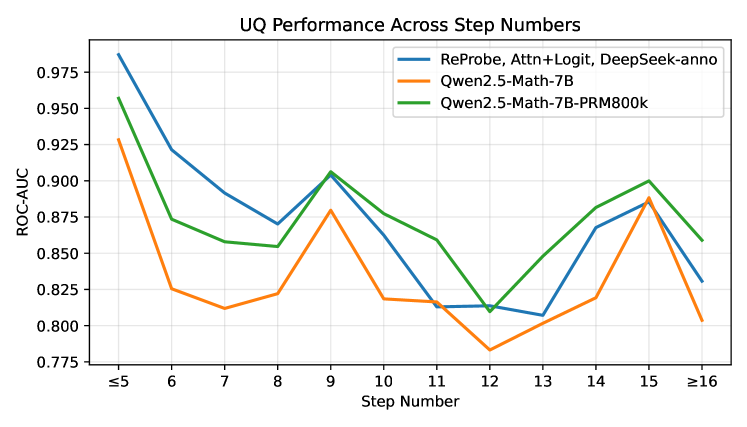
ReProbe replaces bulky Process Reward Models with a <10M-parameter probe that reads directly from the LLM's own hidden states — achieving comparable or better step-level verification at a fraction of the cost.
1 ETH Zürich ·
2 National University of Singapore ·
3 MBZUAI ·
4 University of Zurich ·
University of Melbourne
Model Checkpoints
 JingweiNi/ReProbe_Qwen3-8B_self_anno
Qwen3-8B CoT ReProbe · self-annotated data
JingweiNi/ReProbe_Qwen3-8B_DeepSeek_anno
Qwen3-8B CoT ReProbe · DeepSeek-R1 annotated data
JingweiNi/ReProbe_Qwen3-1.7B_natural_reasoning_GPT-OSS-120B_anno
Qwen3-1.7B native reasoning ReProbe · GPT-OSS-120B annotated data
JingweiNi/ReProbe_Qwen3-32B_GPT-OSS-120B_anno
Qwen3-32B CoT ReProbe · GPT-OSS-120B annotated data
JingweiNi/ReProbe_Qwen3-8B_self_anno
Qwen3-8B CoT ReProbe · self-annotated data
JingweiNi/ReProbe_Qwen3-8B_DeepSeek_anno
Qwen3-8B CoT ReProbe · DeepSeek-R1 annotated data
JingweiNi/ReProbe_Qwen3-1.7B_natural_reasoning_GPT-OSS-120B_anno
Qwen3-1.7B native reasoning ReProbe · GPT-OSS-120B annotated data
JingweiNi/ReProbe_Qwen3-32B_GPT-OSS-120B_anno
Qwen3-32B CoT ReProbe · GPT-OSS-120B annotated data
To load a checkpoint, first set up the target LLM following the GitHub instructions, then attach the probe weights as described in the loading guide.
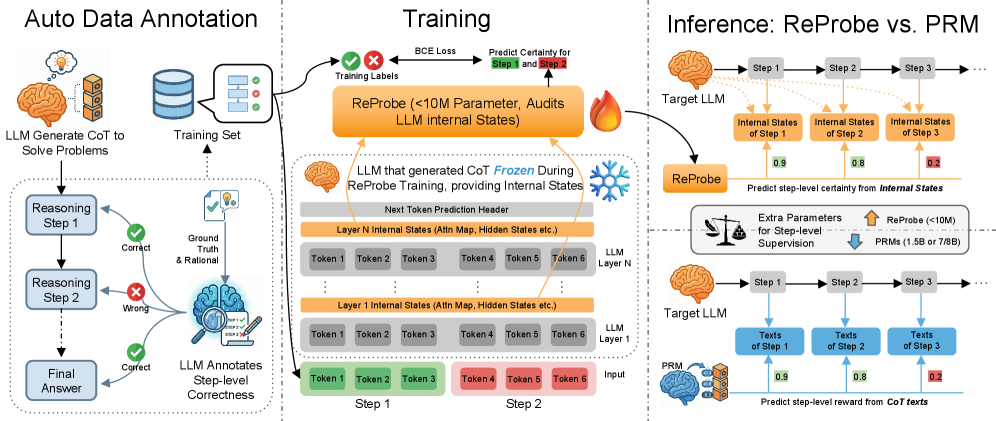
ReProbe training & inference overview. An annotator LLM labels step correctness on CoT traces (left). ReProbe is trained on internal signals from the frozen target LLM (middle). At inference, the tiny probe (<10M params) replaces a 1.5–8B PRM (right).